A New Method for Non-negative Matrix Factorization
What is Non-negative Matrix Factorization?
Non-negative Matrix Factorization (NMF) is an algorithm that decomposes a non-negative matrix
where
The goal is to condense information. Instead of dealing with a large number of data columns (
Multiplicative Update Algorithm
Solving for
where
We want to perform gradient decent to optimize both
For NMF a reasonable loss function is:
Where
And then comes the fun part of evaluating the loss function with respect to W and H
Whew, now we can take these two results and substitute them back into our gradient decent equations for W and H:
Note that the factor of two was "absorbed" into the learning rate (you could also add a 1/2 factor to the loss function, it doesn't really matter). There is an issue with the equations we've written down so far. They contain negative terms! Luckily we still have to define the learning rate parameters which we can set to anything we like. Lee and Seung proposed defining the learning rates as:
which when we substitute into the descent equation gives some nice cancelation:
And these are the two update rules for NMF:
Essentially you pick two random starting points for
Solving NMF with Ordinary Differential Equations
Let's look back at our gradient decent equation:
instead of taking discrete steps toward a local minima, we could look at the limit as we take smaller and smaller step sizes:
This approach is known as gradient flow. When applied to NMF, we end up with a system of coupled differential equations:
Here I'm trying to be explicit about the fact that we are doing an element-wise multiplication, division, and subtraction.
Head-to-Head Comparison
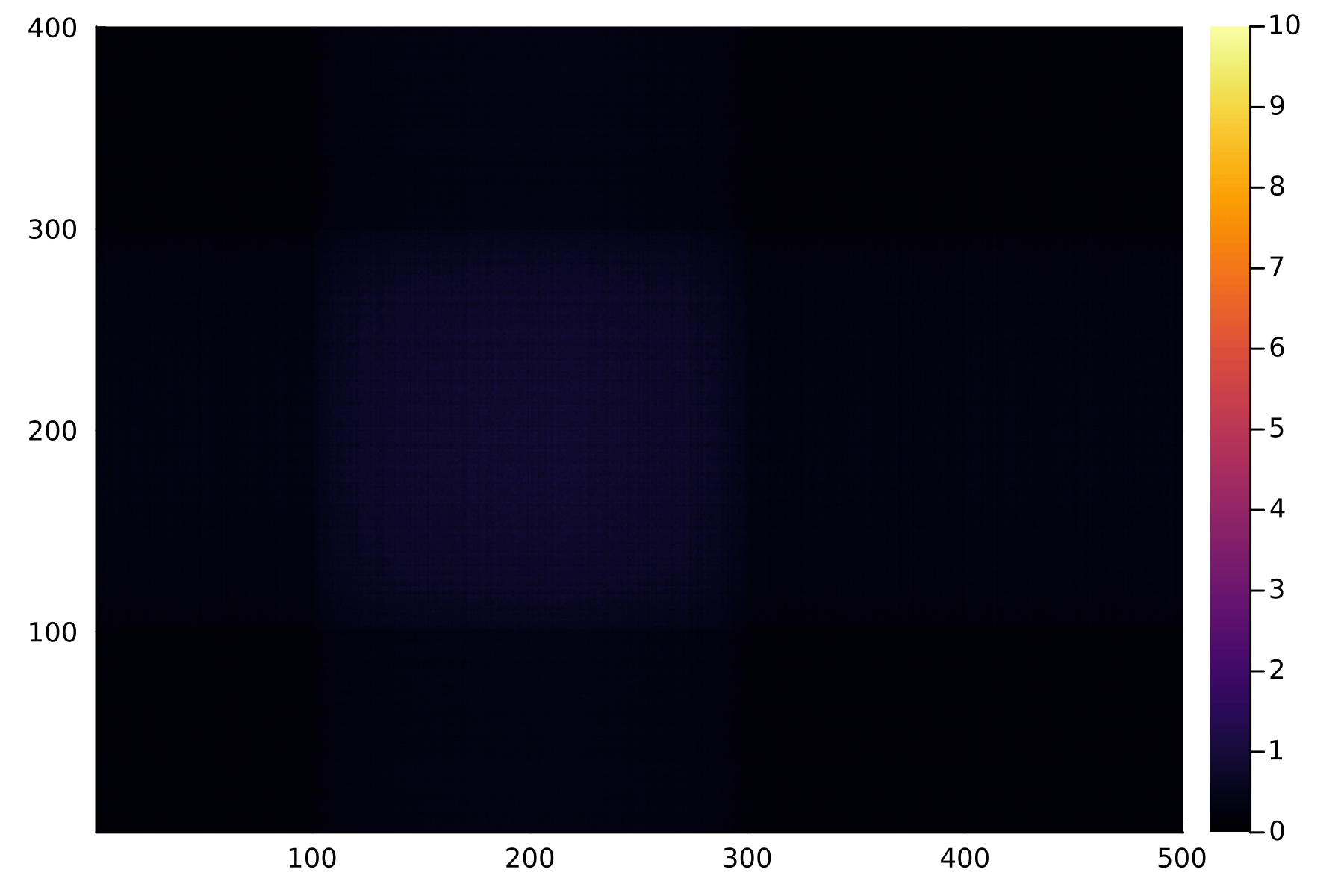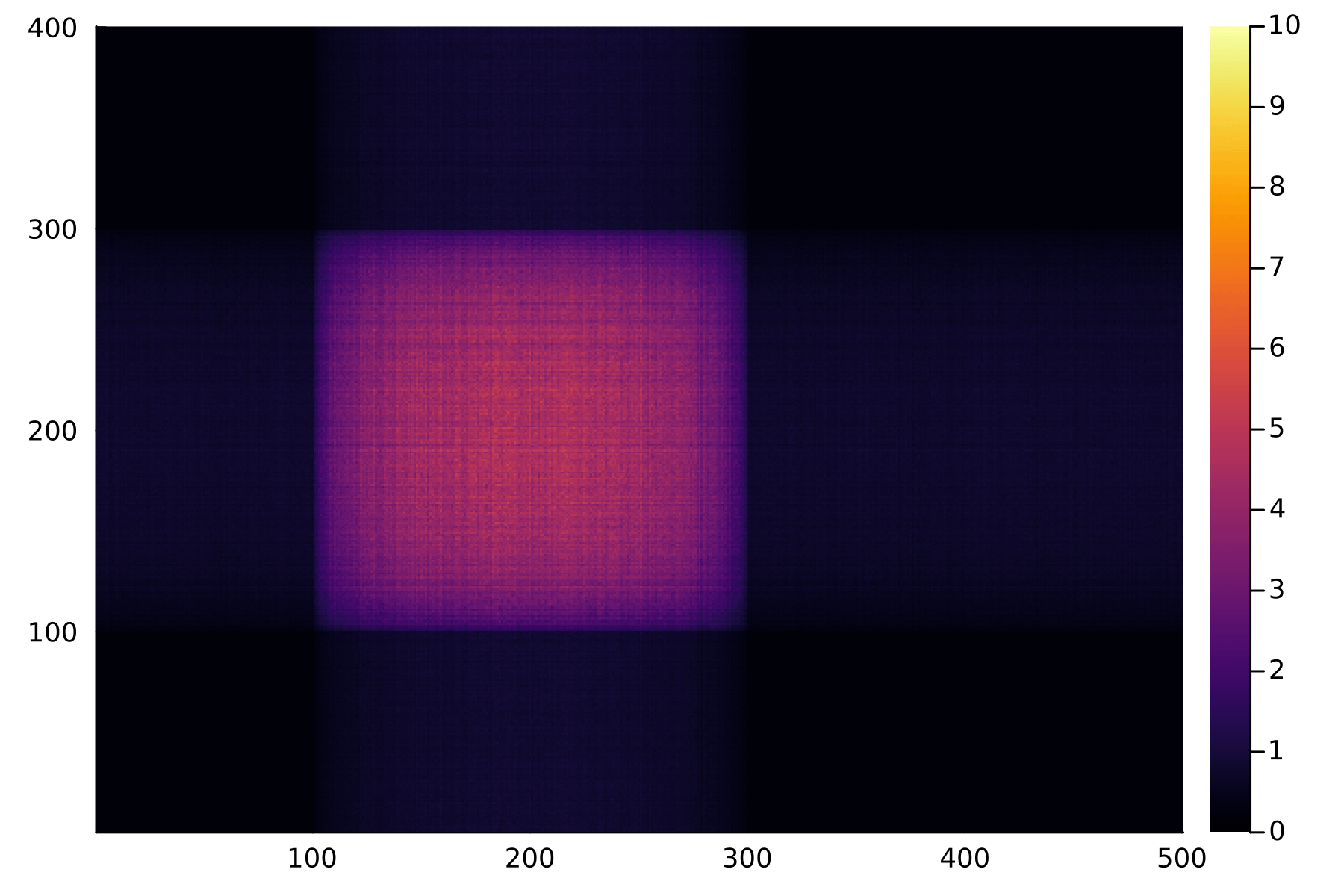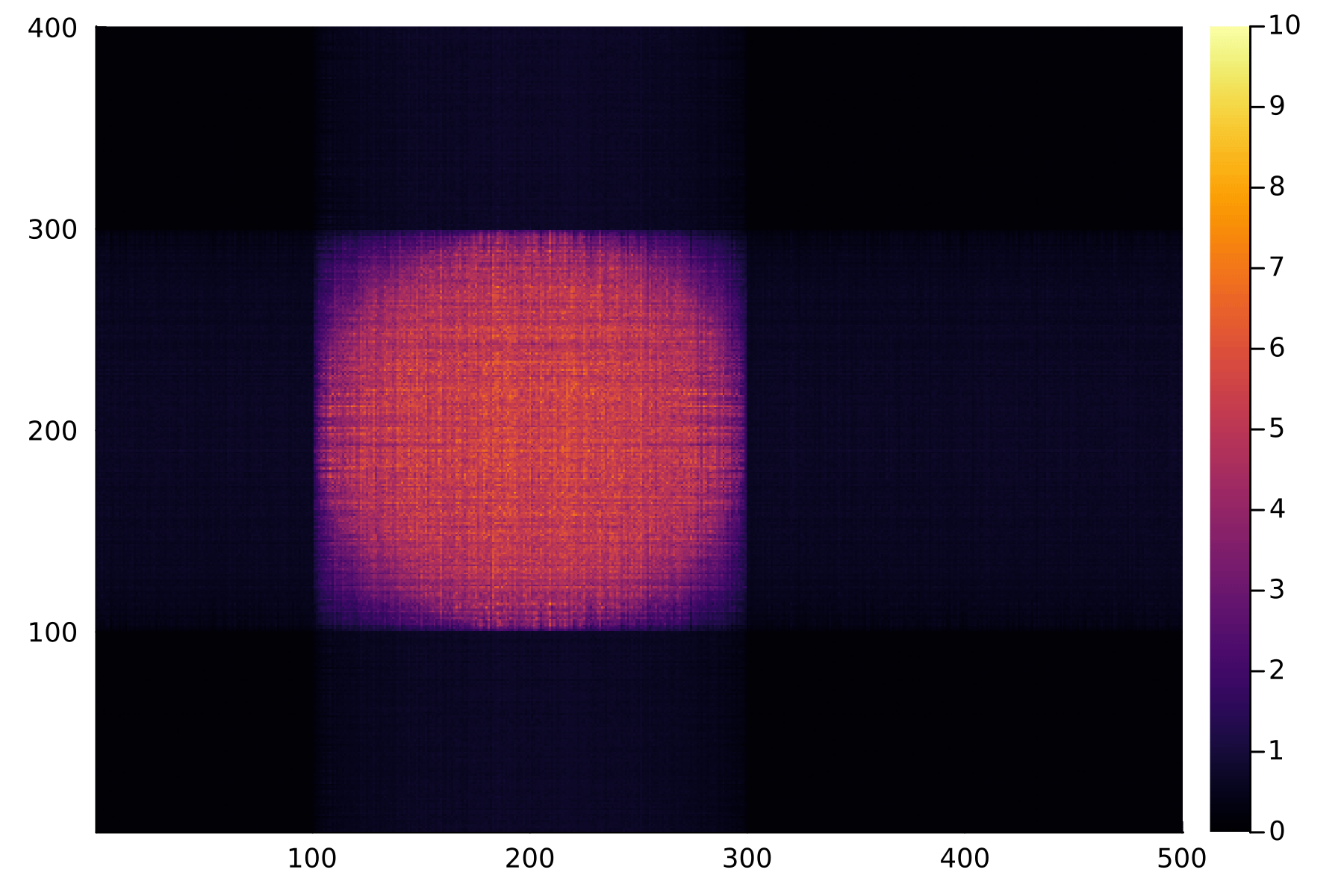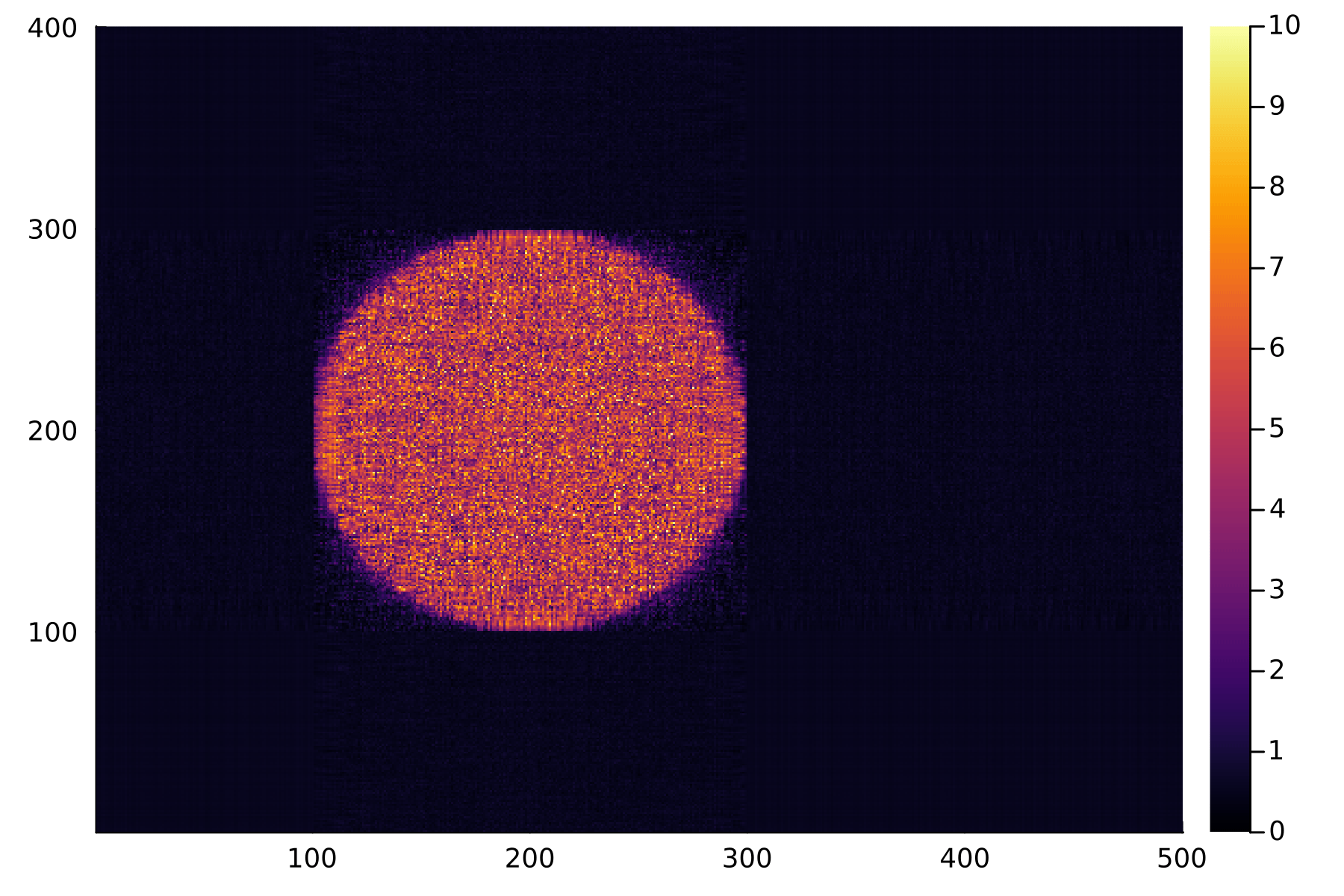
To compare the discrete and continuous versions of these NMF algorithms, I want to focus on overall accuracy as opposed to speed (which will boil down to the number of matrix multiplications performed). I will perform the factorization on the following matrix which defines a circle of random numbers.
using Plots
n,m = (400,500)
k = 40
W0 = rand(n,k)
H0 = rand(k,m)
X = [(x-200)^2+(y-200)^2>50^2 ? rand() : 10*rand() for x in 1:n, y in 1:m]
heatmap(X,clims=(0,10))
The ODE method is going to automatically choose the step size based on the solver choice. To make a fair comparison, I will run the multiplicative update for the same number of iterations.
ODE Implementation
using LinearAlgebra
using OrdinaryDiffEq
using RecursiveArrayTools
# Define ODEs
function nmf!(du, u, p, t)
X, WH, XHᵀ, WHHᵀ, WᵀX, WᵀWH = p
W = u.W
H = u.H
mul!(WH, W, H)
mul!(XHᵀ, X, H')
mul!(WHHᵀ, WH, H')
mul!(WᵀX, W', X)
mul!(WᵀWH, W', WH)
@. du.W = W * (XHᵀ / WHHᵀ - 1)
@. du.H = H * (WᵀX /WᵀWH - 1)
end
WH = similar(X)
XHᵀ = similar(W0)
WHHᵀ = similar(W0)
WᵀX = similar(H0)
WᵀWH = similar(H0)
p = (X, WH, XHᵀ, WHHᵀ, WᵀX, WᵀWH)
u0 = NamedArrayPartition((;W=W0,H=H0))
tspan = (0.0, 1000.0)
#Solving
prob = ODEProblem(nmf!, u0, tspan, p)
sol = solve(prob,ROCK4())I tried a few different ODE solvers and found ROCK4 to be very efficient.
Multiplicative Update Implementation
mutable struct NMFMU{M}
X::M
W::M
H::M
end
nmf = NMFMU(copy(X),copy(W0),copy(H0))
function MU!(nmf::NMFMU)
nmf.W .= nmf.W .* (nmf.X * nmf.H') ./ (nmf.W * nmf.H * nmf.H')
nmf.H .= nmf.H .* (nmf.W' * nmf.X) ./ (nmf.W' * nmf.W * nmf.H)
return nothing
endThis is very inefficient implementation, for an optimized version please use the NMF.jl package.
Loss over Iterations
#error
loss(X,W,H) = norm(X-W*H) / norm(X)
loss(nmf) = loss(nmf.X, nmf.W, nmf.H)
#ODE
ode = [loss(X,sol[i].W,sol[i].H) for i in eachindex(sol)]
pushfirst!(ode,loss(X,W0,H0))
#MU
mu = [loss(X,W0,H0)]
for _ in eachindex(sol)
MU!(nmf)
push!(mu,loss(nmf))
end
plot(ode, label="ODE", linewidth=3, xlabel="Iterations", ylabel="Error")
plot!(mu, label="MU", linewidth=3)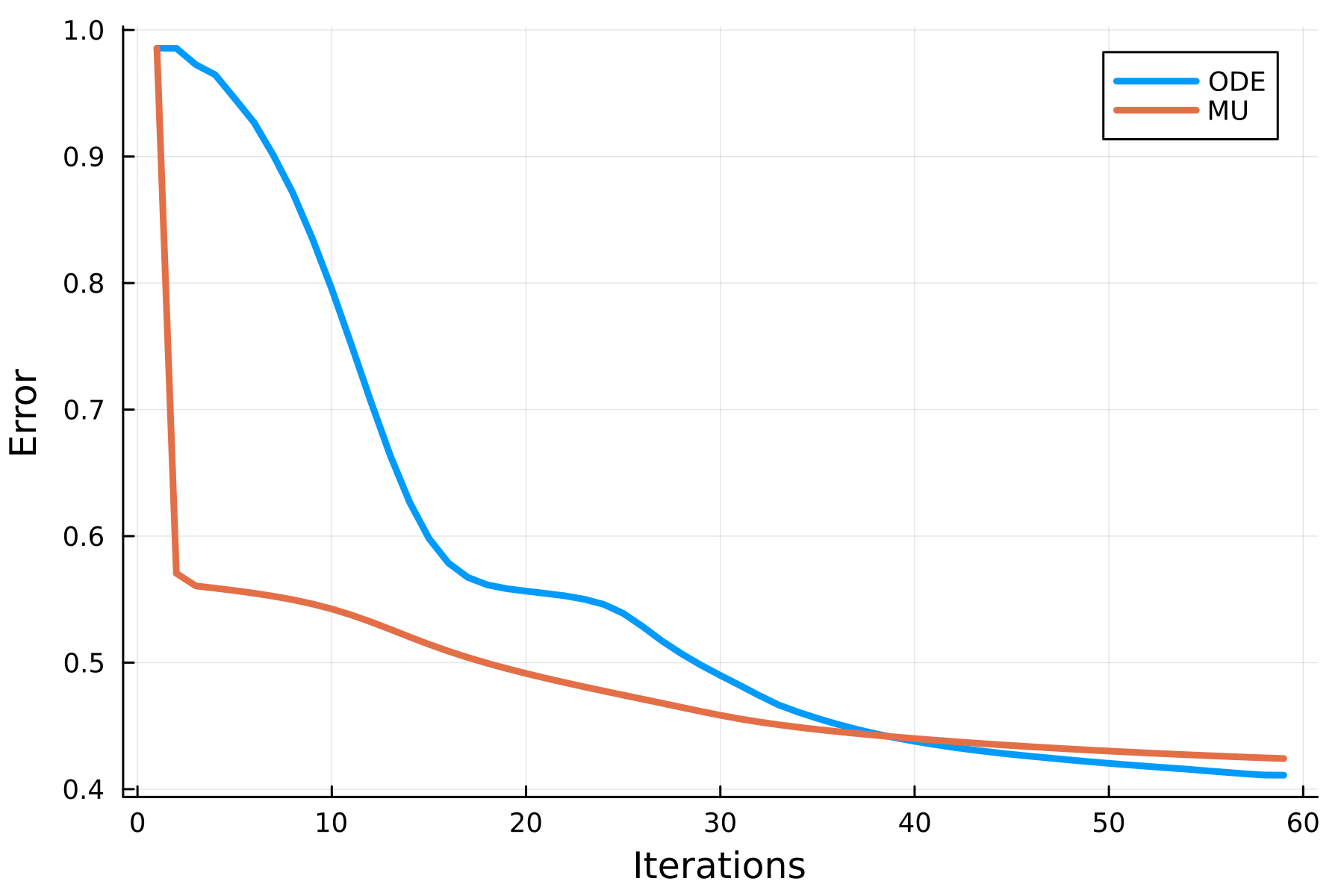
The first thing I notice is the first step each algorithm. MU takes a huge step in the right direction whereas the ODE method is very conservative in its decent. More surprising is that the final solutions are different. At least for this kind of random matrix, the ODE method is able to find a better solution. Maybe MU would eventually end up at the same solution? I've ran these methods for more iterations but this does not seem to be the case.
There are a lot of improvements and variations we can do with this system like accelerated gradient decent, translating more efficient NMF algorithms, and investigating steady state solutions. Hopefully this will lead to better algorithms for NMF!